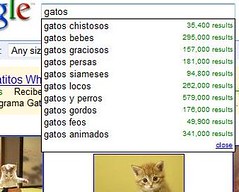
Me he llevado una grata sorpresa al usar el buscador de imágenes de Google. Ahora no sólo te va recomendando búsquedas mientras escribes (a modo de autocompletar), sino que también te indica de forma rápida el número de resultados para cada sugerencia que te hace. Es una funcionalidad que he echado mucho de menos continuamente. Fue algo que me preocupó mucho tiempo durante los 90 cuando aún no desarrollaba para web. La búsqueda en "vivo", "directo" o "interactiva" (creo que ahora lo llaman " en tiempo real") es bastante compleja por el consumo de recursos que requiere frente a lo poco que realmente aporta al usuario. En el caso de las búsquedas sugeridas el coste es escaso. Es una buena aproximación y aporta mucho. Estoy deseando que lo hagan con el buscador web, que es el que uso con más frecuencia.
No pensaba hacerlo, pero ya que hoy todo el mundo habla del nuevo sistema operativo de Google (Chrome OS) y esta entrada va de Google, le dedico esta línea.
Actualizado 23:03: También funciona en las búsquedas de web. Imagino que no me había dado cuenta antes porque suelo buscar desde la barra del navegador.

Lo más visto