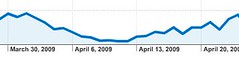
Lentamente el blog se ha recuperado de la gran pifia usando mal Canonical Tag. He recuperado el tráfico orgánico (entrada desde buscadores), mi principal fuente de visitas y que prácticamente había desaparecido. En varias herramientas podía comprobar como mi blog iba dejando de existir en internet. En Google Webmasters Tools, en Páginas con enlaces externos, todas mis páginas fueron desapareciendo hasta quedar únicamente la home. Una vez corregido el problema con la etiqueta Canonical, ha sido paciencia y mucho tiempo, observando lo lento que iba recuperando la llegada de gente desde buscadores, especialmente desde Google.
Tan fuerte fue la pérdida de visitas que un post mío meneado (Usando el API de Google Analytics desde PHP), con todas las visitas que me hizo recibir, no alcanzó para igualar el número habitual. Pero eso no me importó tanto, me hizo mucha ilusión que menearan un post mío.
Ya recuperado, con unos niveles normales de visitas, en los últimos días estoy recibiendo más de lo normal, gran sorpresa, no me lo esperaba, gracias a las entradas El Bruto: ¡Arregla tus cuentas en la arena! y Rayman Raving Rabbids invaden el mundo.

Lo más visto